Data is a foundational aspect of machine learning (ML) that can impact performance, fairness, robustness, and scalability of ML systems.
- Nithya Sambasivan, Research Scientist, Google Research
최근 대학원 졸업과 나의 취업 준비가 진행되면서 내가 어떤 일을 하면서, 어떤 가치관과 어떤 목적성을 가지고 직장을 선택하고, 직무를 고를지에 대한 고민이 계속 되었다. 학창 시절부터 만들고 싶었던 그 누구와도 친구가 될 수 있는 AI에 대한 꿈은 어찌저찌 시대의 흐름을 잘타게 되어 관련 공부를 대학원에서도 할 수 있는 기회도 생겼다. 대학원을 진학할 때와 비슷하게 내가 어떤 역할을 수행하는 사람으로써 AI의 발전에 이바지를 할 수 있을까라는 거창한 생각을 가지며 근 2년간 대학원 연구실에서 진행했던 많은 프로젝트와 학부 때부터 공부해온 언어학적인 지식들을 정리해 갔다.
다양한 종류의 NLP 프로젝트들을 진행하면서 관통되는 시사점은 딱 한 가지였다. 바로 데이터의 중요성이다. 물론 프로젝트가 데이터 구축 관련 프로젝트들이었기 때문에 위와 같은 결론이 도달한 걸 수도 있다. 사실 나도 대학원에 들어와서 AI, NLP에 대해 깊이 공부하기 전까지는 데이터는 AI에 있어 필요한 존재이지, 중요한 존재라고는 생각하지 못했다. 하지만 데이터는 실제로 생각이상으로 중요한 존재였고 필수불가결한 존재이며 다양한 관점에서 섬세하게 구축된 데이터는 모든 AI 연구자, 기업들이 탐내하는 존재라는 것을 깨달았다.
그래서 언어학으로 대학원의 졸업을 앞둔 지금, 학부 4년, 대학원 2년 동안 언어학 지식을 어떻게 효율적으로, 객관적으로, 데이터에 녹여내어 다양한 사람들이 사용할 수 있는 텍스트 데이터를 구축할지 고민하는 내용들을 블로그에 써보고자 한다. 그 과정에서 다양한 사이드 프로젝트로 공개가능한 텍스트 데이터들은 깃허브를 통해 공개할 예정이며 공개과정에서 필요한 legal 이슈들에 대해서도 이번에 함께 공부해보려고 한다.
그 시작으로 데이터와 관련된 내용을 구글링하다가 구글 블로그에서 쓴 글을 정리해보고자 한다.
Data Cascades in Machine Learning
Data Cascade는 AI 개발과정에서 초창기 단계인 데이터 파트에서 나타난 문제들을 간과하고 넘어가면 추후 인공지능 모델 개발 과정에서 이를 수습하기 위해 더 많은 문제를 떠안고 가야한다는 의미의 용어이다.
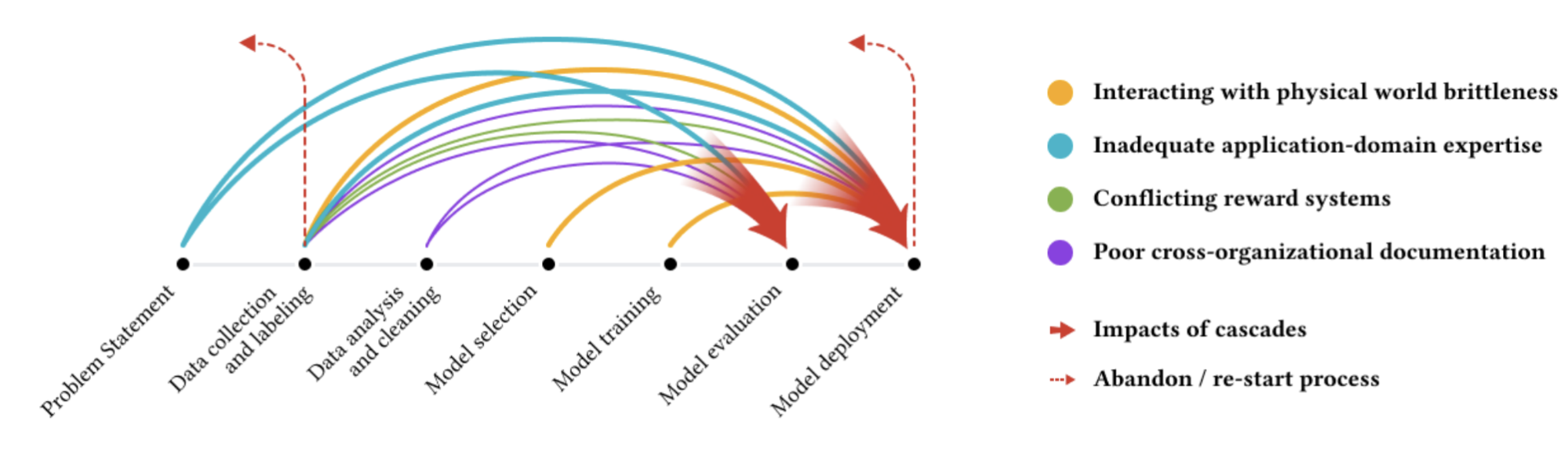
실제로 필자가 속해있는 현업 및 석박사 과정에 있는 다양한 NLP 연구자들이 1500명이나 모여있는 오픈채팅방에서 많은 연구자들이 "끝내는 데이터이다"라는 워딩을 많이 쓰는 것을 볼 수 있다. 하지만 모순적으로 "데이터 작업만 시킨다"라는 말도 함께 나타난다. 실제로 많은 연구자들이 데이터 작업을 기피하는 현상들이 있는 것을 볼 수 있으며, 데이터의 중요성에 비해 그 작업이 간과되는 현상이 있는 것으로 보인다. 하지만 위 블로그에서 소개한 논문인 “‘Everyone wants to do the model work, not the data work’: Data Cascades in High-Stakes AI”에서는 실제로 Data Cascade를 측정하여 논의한 논문으로 그 중요성을 설명한다.
Data Cascade의 예시로 블로글에서는 두 가지 사안을 보여준다(아래의 예시들은 필자가 NLP 도메인에 맞추어 새롭게 넣은 예시이다).
1. 실세계의 데이터와 훈련 데이터의 차이
해결하고자하는 태스크가 정해지면 우선적으로 데이터를 수집하고 이를 정제하는 과정을 거친다. 이 과정에서 잘 정제된 데이터만 모델 훈련의 사용하게 되는데, 이와 같은 경우 모델을 실세계에 나타난 데이터에 적용하려하면 문제가 발생한다. 예를 들어, 리뷰 감성분석을 위해 다양한 리뷰를 수집하고 전처리를 진행할 때, 모든 어휘에 나타난 오타를 교정해주고, 문법적 오류들을 수정해주고, 신조어, 은어와 같은 사전에 나타나지 않는 어휘들을 제거하여 모델을 학습시킨다면, 실제 리뷰에는 당연히 적용이 잘 안될 것이다. 따라서, 이러한 노이즈들을 단순히 제거하거나, 텍스트 데이터의 경우 문법에 맞게 수정해버린다면 실제 나타난 데이터의 노이즈들을 처리하기 힘들 것이다.
2. 전문가의 고견이 생략된 데이터셋
헤드셋 리뷰에 대해 속성 단위 감성 분석(Aspect Based Sentiment Analysis)를 진행한다고 해보자. 헤드셋을 구매하고 리뷰를 작성한 소비자들은 대부분 헤드셋을 구매하기 위해 여러가지 요소들을 고려하여 해당 헤드셋을 선택하고 고려한 요소들에 대해 리뷰를 작성한 것이다. 하지만 평생 헤드셋을 써보지 않은 개발자가 위 프로젝트를 매니징한다면, 데이터를 전처리하는 과정에서, 혹은 분류가 필요한 속성 표현을 추출하는 과정에서 실제로는 중요한 데이터들이 누락되거나 변형될 수도 있다. 예를 들어, "거리감이 생각보다 괜찮았어요"라는 리뷰가 있을 때, 헤드셋을 잘 모르는 사람이 해당 리뷰를 본다면 거리감이 왜 필요한지 이해하기 쉽지 않을 것이다. 여기서 거리감은 헤드셋을 꼈을때 소리가 들리는 거리감을 의미하는 것으로 하나의 속성 표현으로 세분화 될 수 있는 요소 중 하나로 볼 수 있다.
하지만 실제 현업에서는 매 태스크만다 전문가에 대한 의견을 참고하기에는 실질적으로 힘들기에 위와 같은 현상이 많이 발생한다고 한다. 이러한 경우도 Data Cascade의 시발점이 될 수 있다고 위 글에서는 주장한다.
그럼 해결법은?
위 블로그에서는 다양한 부분에서 체계적으로 접근해야 해결이 가능한다고 설명한다.
- 데이터 품질에 대한 개념 확립
- ML 시스템이 사용하는 데이터의 품질을 모델의 적합성과 유사한 개념으로 고려한다.
- 현상의 정확성 및 포괄성을 나타내는 F1-score와 같은 표준화된 메트릭을 개발하고 사용하여 데이터 품질을 측정한다.
- 데이터에 대한 인센티브 혁신
- 데이터 작업에 대한 노력을 인정하기 위해 데이터에 관한 경험을 즐겁게 받아들이고, 기업에서 데이터 관리 및 조직 내 데이터 작업에 대한 보상을 강조한다.
- 팀 간 협력 강화
- 데이터 작업은 여러 역할과 팀 간 협력을 요구하지만, 협력이 제한적인 경우가 많다.
- 데이터 수집자, 전문가 및 ML 개발자 간의 협력, 투명성, 이익 분배에 중점을 두어 협업을 촉진한다.
- 글로벌 데이터 불평등 해소를 위한 노력
- 하위 소득 국가에서는 데이터 부족이 심각한데, 이로 인해 ML 개발자는 새로운 데이터를 정의하고 정비하는 데 어려움을 겪는다.
- 글로벌 데이터 뱅크 구축, 데이터 정책 개발, 정책 제정자 및 시민 사회에게 ML에 대한 교육을 강화하여 데이터 불평등 문제를 해결한다.
시사점
대부분 학습에 필요한 데이터는 크라우드 소싱 형태로 계약직을 통해 데이터를 구축하는 경우가 많다. 크라우드 소싱이 가져오는 다양한 이점이 분명 존재하겠지만, 만약, 충분히 검증을 거치지 않은 작업자가 데이터를 구축한다면, 그 데이터의 퀄리티가 떨어질 가능성도 분명히 존재한다. 따라서 Data Cascade를 피하기 위해서는 구축단계에서 구축자에 대한 전문성(텍스트 데이터의 경우 언어학 혹은 국어학 등을 공부했거나 자격증이 있는 경우)을 띄는 작업자를 선별하거나, 작업 중간중간 데이터의 일관성이 나타나는 지 확인하는 파이프라인이 존재하는 것이 좋을 것으로 보인다.
https://blog.research.google/2021/06/data-cascades-in-machine-learning.html
Data Cascades in Machine Learning
Nithya Sambasivan, Research Scientist, Google Research Data is a foundational aspect of machine learning (ML) that can impact performance, fairness, robustness, and scalability of ML systems. Paradoxically, while building ML models is often highly prioriti
blog.research.google
https://research.google/pubs/pub49953/
"Everyone wants to do the model work, not the data work": Data Cascades in High-Stakes AI – Google Research
AI models are increasingly applied in high-stakes domains like health and conservation. Data quality carries an elevated significance in high-stakes AI due to its heightened downstream impact, impacting predictions like cancer detection, wildlife poaching,
research.google
'Study > NLP' 카테고리의 다른 글
| Korean RAG - with gemini (2) | 2024.01.28 |
|---|---|
| Emotion Analysis (감정 분석) (4) | 2023.12.20 |
| 한국어 띄어쓰기 모델 (0) | 2023.11.16 |
| 감성 분석이란? (0) | 2023.11.16 |
| 자연어처리란? (0) | 2023.11.16 |




댓글