이 글은 '머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로' 책을 읽고 정리한 것이다.

머신러닝(machine learning)이란 데이터가 넘치는 현대 사회에서 데이터들을 이해하여 지식으로 바꾸는데 요긴한 하나의 수단이다. 요컨대, 수많은 데이터를 우리가 직접 하나하나 이해하는 것이 아니라, 머신러닝 알고리즘을 이용해 기계가 스스로 데이터들을 학습하여 우리에게 유용한 정보를 제공해주는 것을 말한다.
이 장에서 우리가 배울 것은
-
머신 러닝의 일반적인 개념
-
세 종류의 학습과 기본 용어
-
성공적인 머신 러닝 시스템을 설계하는 필수 요소
-
데이터 분석과 머신 러닝을 위한 파이썬 설치
1.1 데이터를 지식으로 바꾸는 지능적인 시스템 구축
20세기 후반 데이터에서 지식을 추출해서 예측하는 자기 학습 알고리즘과 관련된 인공 지능의 하위 분야로 머신 러닝이 나타났다. 위에서 언급했다시피 사람이 수동으로 대량의 데이터를 분석하기보다 머신 러닝이 더 효율적으로 데이터를 분석하고 지식을 추출하여 예측 모델과 데이터 기반의 의사 결정 성능을 향상시킬 수 있다. 이러한 기능은 일상생활에도 다방면으로 적용되며 우리의 삶을 더욱 윤택하게 해주고 있다.
1.2 머신 러닝의 세 가지 종류
-
지도 학습(supervised learning)
지도 학습의 목적은 훈련된 데이터에서 모델을 학습하여 본 적 없는 미래의 데이터에 대한 예측을 하는 것이다. 여기서 지도(supervised)란 희망하는 출력 신호가 있는 일련의 샘플을 의미한다. 즉, 레이블이 된 훈련 데이터(결과가 명확한 데이터)를 바탕으로 수학적 예측 모델을 형성하고 이를 바탕으로 새로운 데이터의 결과를 예측하는 기술이다.
지도 학습은 분류(classification)와 회귀(regression)로 세분화가 가능하다. 우선 분류는 범주형 값을 예측하는 것을 목적으로 한다. 예컨대, 스팸 메일을 필터링을 생각해보면, 메일을 스팸메일과 아닌 것 두 가지 범주(이진 분류)로 구분하여 분류한다. 하지만 꼭 두 가지 클래스 레이블(범주)만 잇는 것이 아니라 두 개 이상인 경우도 많다. 이를 다중 분류(multiclass classification)이라 한다. 전형적인 예로는 손글씨 인식이다. 손으로 쓴 글자들을 모아 훈련 데이터로 구성한 후 새로운 글자를 입력하면 예측 모델이 일정한 정확도로 글자를 예측하는 것이다.
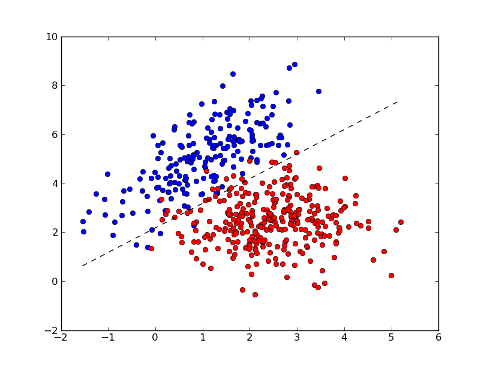
회귀는 분류와는 다르게 연속적인 출력 값을 예측하는 것을 말한다. 쉽게 말해서 분류는 데이터들의 범주형 순서가 없었지만 회귀는 출력 값이 존재한다. 회귀는 예측(입력 혹은 설명) 변수와 반응(출력 혹은 타깃) 변수 사이의 관계를 찾아 출력 값을 예측한다.

x축과 y축은 각각 예측 변수와 반응 변수를 나타낸다. 그리고 다이아몬드 모양이 각 변수들의 출력 값이며 그 값들의 평균 직선의 기울기와 절편이 새로운 데이터들의 출력 값을 예측하는 것이다.
-
강화 학습(reinforcement learning)
강화 학습은 환경과 상호 작용하여 시스템의 성능을 최적화시켜주는데 그 목적이 있다. 환경의 상태 정보에는 보상 신호를 포함하고 있기 때문에 이를 지도 학습과 관련된다고 볼 수도 있다. 하지만 지도 학습과는 다르게 강화 학습의 피드백은 정답 레이블이 아니다. 대신 보상 함수를 바탕으로 얼마나 좋은 행동인지를 측정한 값을 주는 것이다. 여러 시행착오를 통해 시스템(에이전트)은 환경과 상호작용하여 보상이 최대화되는 행동을 학습한다. 요컨대, 어떠한 환경에서 존재하는 에이전트가 현재의 상황을 인식하고 할 수 있는 여러 가지 행동들 중에서 가장 좋은 보상을 얻을 수 있는 행동을 선택하는 것을 말한다.

보상은 좋은 보상만 존재하는 것이 아니라 음의 보상도 존재한다. 체스 게임을 예로 들어보면, 체스판에서(환경) 하나의 말(에이전트)을 여러 가지 방향 중 한 가지 방향을 선택해서 움직였을 때(행동) 주어지는 보상은 '바로 상대방 말을 잡는다(양의 보상)'과 '바로 상대방 말에게 잡힌다(음의 보상)'인 즉시 피드백이 주어질 수도 있고, '차후에 상대방 말을 잡기 좋은 위치에 놓였다'와 같은 지연된 피드백이 주어질 수도 있다. 이런 피드백들을 바탕으로 보상을 최대화하는 일련의 과정을 학습해가는 과정이다.
-
비지도 학습(unsupervised learning)
지도 학습과 강화 학습은 모두 일정의 데이터와 그 데이터에 대한 정답 혹은 보상의 정도가 주어졌다. 하지만 비지도 학습에서 사용되는 데이터는 레이블 되지 않았거나 구조를 알 수 없는 데이터를 다룬다. 비지도 학습에서 데이터를 분류하는 방법으로는 군집(clustering)이 있다. 군집은 미분류된 데이터를 유사한 데이터끼리 모아 하나의 서브그룹 혹은 클러스터(cluster)로 분류하는 데이터 분석 기법이다. 분류된 클러스터들은 유사성을 공유하기에 클러스터 내부에서 패턴을 찾을 수가 있다. 또 다른 하위 분야로는 차원 축소(dimension reduction)가 존재한다. 대체로 정제되지 않은 데이터(raw data)는 여러 가지 변수를 포함하고 있는 고차원의 데이터이다. 이런 데이터의 처리를 좀 더 용이하게 하기 위해 여러 가지 변수들을 줄이는 전처리의 과정을 차원 축소라 한다. 원하는 작업과 관련이 없는 변수들을 줄임으로서 데이터 간의 유의미한 관계를 도출하기 편리해지는 것이다. 이러한 차원 축소는 데이터의 시각화 과정에도 유용하다.


1.3 기본 용어와 표기법 소개
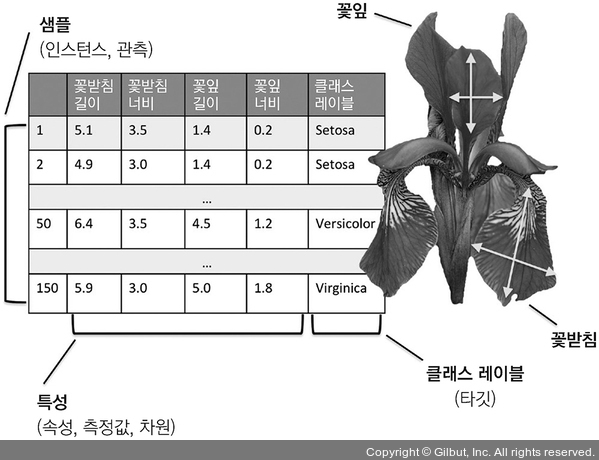
위의 예시를 통해 용어를 설명하면, 각 붓꽃의 샘플은 데이터셋에서 하나의 행으로 표현된다. 각 측정값은 열에 저장되며, 이를 특성(feature)이라고 한다. 기초적인 선형대수학(linear algebra)을 통해 효율적으로 코드를 구현할 수 있게 한다. 따라서 앞으로는 행렬(matrix)과 벡터(vector) 표기로 데이터를 표현한다.
1.4 머신 러닝 시스템 구축 로드맵

1.4.1 전처리 : 데이터 형태 갖추기
주어지 원본 데이터의 형태가 학습 알고리즘에서 사용하기에 최적의 성능을 내기에 적합한 경우는 매우 드물다. 따라서 우리는 전처리라는 단계를 통해 원본 데이터를 학습 알고리즘에서 최적의 성능을 낼 수 있게 가공을 해준다. 이는 머신 러닝 애플리케이션에서 가장 중요한 단계이다. 다수의 머신 러닝 알고리즘에서 최적의 성능을 내기 위해선 선택된 특성이 같은 스케일이어야 한다. 이를 위해서 특성을 [0,1]의 범위로 변환하거나 표준 정규 분포(standard normal distribution)로 변환하는 경우가 많다.
중복된 정보를 가진 특성은 차원 축소 기법을 사용하여 특성을 압축한다. 이렇게 하면 저장공간을 덜 차지하고 학습 알고리즘 또한 빠르게 실행할 수 있다. 어떤 경우에는 예측 성능도 높이기도 한다. 이는 데이터셋에 관련 없는 특성이 많을 경우, 신호 대 잡음비(Signal-to Noise Ratio, SNR)가 낮은 경우이다.
차후에 머신 러닝의 알고리즘이 잘 작동하는지 확인하기 위해 데이터 셋을 랜덤 하게 훈련 데이터셋과 테스트 데이터셋으로 나누어야 한다. 훈련 데이터셋은 머신 러닝을 훈련하고 최적화하며 테스트 데이터셋에선 최종 모델을 평가하는 데 사용된다.
1.4.2 예측 모델 훈련과 선택
모든 문제를 해결할 한 가지 머신 러닝 알고리즘이 있다면 엄청나겠지만 그런 알고리즘은 현재까지 존재하지 않다. 여러 머신 러닝 알고리즘은 각기 다른 문제를 해결하기 위해 구성되어있다. 실제로 효과적인 머신 러닝 알고리즘을 만들기 위해선 최소한 몇 가지 알고리즘을 비교해야 한다. 비교하기 전에 우선적으로 성능을 측정할 지표를 결정해야 한다. 여러 지표 중 가장 널리 사용되는 지표는 정확도(accuracy)이다. 이는 정확히 분류된 샘플의 비율이다. 테스트 데이터셋과 실제 데이터셋에서 어떤 모델이 더 잘 작동하는지 알기 위해선 두 가지 기법을 활용하여 측정할 수 있다. 하나는 교차 검증 기법이다. 모델의 일반화 성능을 예측하기 위해 훈련 데이터를 훈련 데이터셋과 검증 데이터셋으로 한 번 더 나눈 것이다. 다음은 하이퍼 파라미터(hyperparameter) 최적화 기법이다. 이 기법은 데이터에서 학습하는 파라미터가 아닌 모델 성능을 향상하기 위해 사용하는 다이얼로 볼 수 있다.
1.4.3 모델을 평가하고 본 적 없는 샘플로 예측
최적의 모델을 선택한 후에는 테스트 세트를 사용하여 이전에 본 적 없는 데이터를 통해 얼마나 성능을 내는지 예측하여 일반화 오차를 예상한다. 이 서능에 만족하면 이 모델을 통해 미래의 새로운 데이터를 예측할 수 있다.
1.5 머신 러닝을 위한 파이썬
파이썬은 데이터 과학 분야에서 가장 인기 잇는 프로그래밍 언어이다. 계산량이 많은 작업에서 파이썬과 같은 인터프리터 언어의 성능이 저수준 프로그래밍 언어보다 낮다. 하지만 넘 파이(NumPy), 사이파이(SciPy), 사이킷런(Scikit-learn)과 같은 라이브러리를 통해 다차원 배열에서 벡터화된 연산을 빠르게 수행할 수 있습니다.
1.5.1 파이썬과 PIP에서 패키지 설치
파이썬은 window, mac, linux 세 개의 주요 운영 체제에서 모두 사용 가능하다. 앞으로의 파이썬은 3.7.2 버전 그 이상에 맞추어져 있다. 예제는 대부분 2.7.13 버전 이상에서 호환이 될 것이다. 2.7 버전을 사용한다면 파이썬 2와 3의 차이를 잘 알아야 한다(https://wiki.python.org/moin/Python2orPython3 참조). 파이썬 공식 웹 사이트(https://www.python.org)에서 파이썬을 설치한 후 pip를 통해 패키지들을 설치할 수 있다. 파이썬을 환경변수의 path설정을 한 후, 터미널에서 간단한 pip 명령어로 패키지를 설치할 수 있다.
> pip install 패키지 이름
업그레이드가 필요할 때에는 아래의 코드를 사용한다.
> pip install --upgrade 패키지 이름
1.5.2 아나콘다 파이썬 배포판과 패키지 관리자 사용
과학 컴퓨팅을 위해선 아나콘다(Anaconda) 파이썬 배포판을 권장한다. 이는 데이터 과학, 수학, 공학용 파이썬 필수 패키지들을 모두 포함하고 있어 편리하다. 다운로드는 https://www.anaconda.com/download/에서 받을 수 있다.
필요 패키지 설치를 위해선
> conda install 패키지 이름
업데이트 시에는 아래의 코드를 사용한다.
> conda update 패키지 이름
1.5.3 과학 컴퓨팅, 데이터 과학, 머신 러닝을 위한 패키지
- NumPy 1.16.1 : 데이터를 저장하고 조작하는 데 사용
- SciPy 1.2.1
- Scikit-learn 0.20.2
- Matplotlib 3.0.2 : 데이터를 시각화하는 데 사용
- Pandas 0.24.1 : 테이블 형태의 데이터를 쉽게 다루기 위해 사용
- TensorFlow 2.0.0
1.6 요약
- 지도 학습의 주요 하위 분야는 분류와 회귀
- 비지도 학습은 레이블 되지 않은 데이터에서 구조를 찾기에 유용한 기법
- 비지도 학습은 전처리 단계에서 데이터 압축에도 유용하게 사용됨
- 파이썬 환경 구성
'Study > ML&DL' 카테고리의 다른 글
| 10. 회귀 분석으로 연속적 타깃 변수 예측 (0) | 2020.03.17 |
|---|---|
| 8. 감성분석에 머신 러닝 적용 (0) | 2020.03.03 |
| 6. 모델 평가와 하이퍼파라미터 튜닝 (0) | 2020.02.18 |
| 5. 차원 축소를 사용한 데이터 압축 (0) | 2020.02.10 |
| 2. 간단한 분류 알고리즘 훈련 (0) | 2020.01.20 |




댓글