알고리즘을 미세 조정하여 높은 성능의 머신 러닝 모델을 만들고 성능을 평가하기
- 편향되지 않은 모델 성능 추정
- 머신 러닝 알고리즘에서 일반적으로 발생하는 문제 분석
- 머신 러닝 모델 세부 튜닝
- 여러 가지 성능 지표를 사용하여 모델 예측 성능 평가
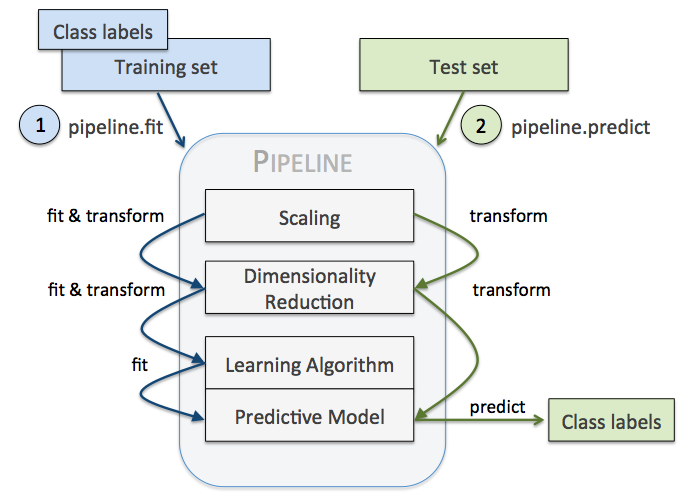
6.1 파이프라인(Pipeline)
여러 개의 변환 단계를 포함한 모델을 학습하고 새로운 데이터에 대한 예측을 생성할 수 있다. 사이킷런의 변환기 중 fit / transform 메서드를 지원하는 객체에 한에서 make_pipeline 함수를 이용해 연결이 가능하다.
##PCA를 통해 30차원의 데이터를 2차원으로 낮추기
#StandardScaler, PCA, LogisticRegression을 하나의 파이프라인으로 연결
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
pipe_lr = make_pipeline(StandardScaler(),
PCA(n_components=2),
LogisticRegression(solver='liblinear', random_state=1))
pipe_lr.fit(X_train, y_train) #pipline에 묶여있는 모든 변환기의 fit과 transform 메서드를 차례로 거쳐 추정기 객체에 도달한다.
y_pred = pipe_lr.predict(X_test) #predict 메서드는 마지막 추정기 객체가 변환된 데이터의 예측을 반환한다.위의 pipeline 예시를 분석해보면 우선적으로 StandardScaler의 fit과 transform 메서드를 거쳐 변환된 데이터를 PCA 객체로 전달되어 저차원으로 변환한 후 LogisticRegression 모델이 변환된 데이터로 학습을 한다. 중간단계의 개수 제한은 없지만 중요한 점은 마지막 단계는 항상 추정기가 되어야 한다는 점이다.
6.2 k-겹 교차 검증
6.2.1 홀드 아웃 교차 검증(holdout cross-validation)

- 초기 데이터셋을 별도의 훈련 세트(모델 훈련용)와 테스트 세트(일반화 성능 추정용)로 나눈다.
모델 선택(예측 성능을 높이기 위해 하이퍼파라미터를 튜닝하고 비교하는 과정 중 최적의 파라미터를 선택하는 것)에서 테스트 세트를 지속 적용하면 과대 적합이 된다.
2. 홀드 아웃에선 훈련세트를 다시 훈련 세트(여러 가지 모델 훈련), 검증 세트(최적의 파라미터가 나올 때까지 반복적으로 모델 성능 평가)로 나눈다.
3. 그 후에 기존에 사용하지 않은(모델 입장에선 처음 마주친) 테스트 세트를 통해 성능평가 실시한다.
하지만 위의 방식은 훈련 데이터를 어떤 방법으로 검증가 훈련 데이터 세트로 나누냐에 따라 성능 추정이 민감할 수 있다.
6.2.2 k-겹 교차 검증
k-겹 교차 검증은 중복을 허락하지 않는다. 즉, 검증에 한 번만 사용된다는 장점이 있다.
방식은 아래와 같다.
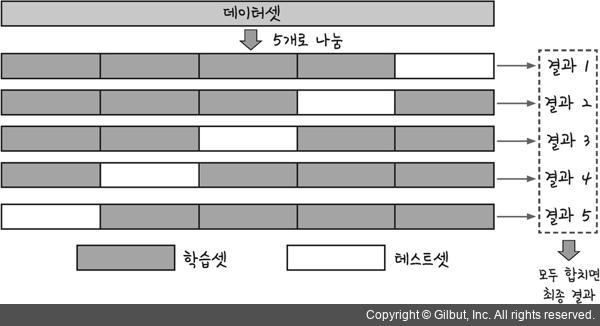
- 훈련 데이터셋을 k개의 폴드로 랜덤하게 나눈다.
- k-1개의 폴드로 모델을 훈련하고 남은 한 개로 모델을 평가한다.
- 이 과정을 k번 반복하여 k개의 모델과 성능 추정을 얻는다.
- 독립적인 모델들의 평균 성능을 계산(주로 최적의 파라미터를 찾기 위해 사용) 한다.
- 최적의 파라미터를 찾은 후엔 전체 훈련 세트를 사용하여 모델을 다시 훈련한다. (전체 세트를 사용하는 이유는 훈련 세트가 클수록 알고리즘이 더 정화하고 안정적이기 때문이다.)
- 독립적인 테스트 세트를 사용해서 최종 성능을 추정한다.
6.3 학습 곡선과 검증 곡선
학습 곡선을 사용하면 모델이 과대적합 되었는지 과소 적합인지를 판별 가능하다. 모델이 과대 적합인 경우에는 더 많은 훈련 데이터를 모으거나, 모델 복잡도를 낮추거나, 규제를 증가시켜 해결할 수 있다. 규제가 없는 모델에서는 특성 선택이나 특성 추출을 통해 특성 개수를 줄여 과대 적합을 감소시킬 수 있다. 모델이 과소 적합되었을 경우에는 모델의 파라미터 개수를 늘리는 것이다.
검증 곡선은 과대, 과소 적합 문제를 해결하여 모델 성능을 높일 수 있는 유용한 도구이다. 학습 곡선과의 차이점은 샘플 크기의 함수로 훈련 정확도와 테스트 정확도를 그리는 대신 모델 파라미터 값을 함수로 그린다.
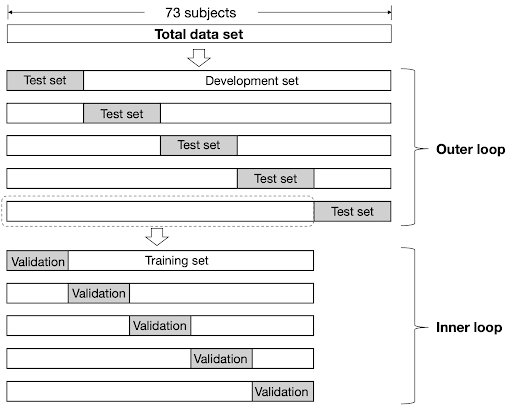
6.4 그리드 서치
리스트로 지정된 여러 하이퍼파라미터 값 전체를 조사한다. 그 후 리스트의 모든 조합에 대하여 최적의 조합을 찾아낸다.
중첩 교차 검증(nested cross-validation)을 사용하면 테스트 세트에 대한 추정 오차는 거의 편향되지 않는다. 따라서 이런 방식은 계산 성능이 중요한 대용량 데이터셋에 유용하다.
6.5 여러 가지 성능 평가 지표
- 오차 행렬

이 오차 행렬에 나타나는 정보를 이용해서 여러 가지 오차 지표를 계산할 수 있다.
계산 가능한 지표들로는 예측 오차(ERR), 정확도(ACC), 진짜 양성 비율(TPR), 거짓 양성 비율(FPR), 정확도(PRE), 재현율(REC), F1-점수다.
- ROC (Receiver Operating Characterisrtic) 곡선
임계값을 바꾸어 계산된 FPR과 TPR 점수를 기반으로 분류 모델을 선택할 수 있는 유용한 도구이다. 대각선 기준으로 아래의 모델은 랜덤 추측보다 안 좋은 모델임을 뜻한다. 완벽한 분류기는 TPR이 1이고 FPR이 0인 왼쪽 위 구석에 위치한 분류기이다. ROC 곡선 아래의 면적인 ROC AUC(ROC Area Under the Curve)를 계산해서 모델의 성능을 종합할 수 있다.
- 다중 분류의 성능 지표
마크로(macro)와 마이크로(micro) 평균 방식을 구현하여 OvA(One-versus-All) 방식을 사용하는 다중 분류이다. 마이크로는 각 샘플이나 예측에 동일한 가중치를 부여하고자 할 때 사용된다. 마크로는 모든 클래스에 동일한 가중치를 부여하여 분류기의 전반적인 성능을 평가한다. 가중치가 적용된 마크로 평균은 레이블마다 샘플 개수가 다른 불균형한 클래스 다룰 때 유용하다.
6.6 불균형한 클래스 다루기
불균형한 데이터셋에서는 정확도를 모델 성능 비교의 지표로 쓰기보다는 다른 지표를 활용하는 것이 낫다. 모델을 적용할 대상의 주요 관심이 무엇인지에 따라 정밀도, 재현율, ROC 곡선 등이 지표로써 활용될 수 있다.
불균형한 클래스를 다루는 방법에는 다음과 같은 방법들이 있다.
- 소수 클래스에서 발생한 예측 오류에 큰 벌칙을 부여
- 소수 클래스의 샘플을 늘리기
- 다중 클래스의 샘플을 줄이기
- 인공적인 훈련 샘플을 생성
'Study > ML&DL' 카테고리의 다른 글
| 10. 회귀 분석으로 연속적 타깃 변수 예측 (0) | 2020.03.17 |
|---|---|
| 8. 감성분석에 머신 러닝 적용 (0) | 2020.03.03 |
| 5. 차원 축소를 사용한 데이터 압축 (0) | 2020.02.10 |
| 2. 간단한 분류 알고리즘 훈련 (0) | 2020.01.20 |
| 1. 컴퓨터는 데이터에서 배운다. (0) | 2020.01.11 |




댓글